Introducing a new feature: Search
We are delighted to announce the publication of a prototype search page, Search, which allows users of our edition to explore the interpretive text of Fr20125 and Royal 20 D I. Currently, our interpretive text includes Eneas in both manuscripts, and Rome II and the Conquest of Gaul by Caesar in Fr20125.
The new search tool represents an important milestone in our work. Search is the result of our collaboration with the team of the Dictionnaire Étymologique de l’Ancien Français (DEAF). It supports the edition by providing a guide to understanding and interpreting the text, and opens up future possibilities for the digital analysis of Old French texts. The page is still under development so we are testing both the accuracy of the data and the functionality of the interface. Feedback is very welcome and much appreciated. If you can help us (reporting bugs or mistakes), please get in touch (by email or through TVOF’s social media pages).
What can you search for? Forms and lemmata
By entering a string of letters in the field ‘Lemma or Form’, the search page allows you to search for every occurrence of:
- a single form, i.e. a word, exactly as it appears in the text, including the morphological elements (such as verb endings and flectional marks) and the particularities of the spelling;
- a lemma (plural: lemmata), i.e. a headword under which flexed or variant forms are grouped: e.g. the infinitive for verbs, the singular cas régime for nouns, the subject pronoun for personal pronouns.
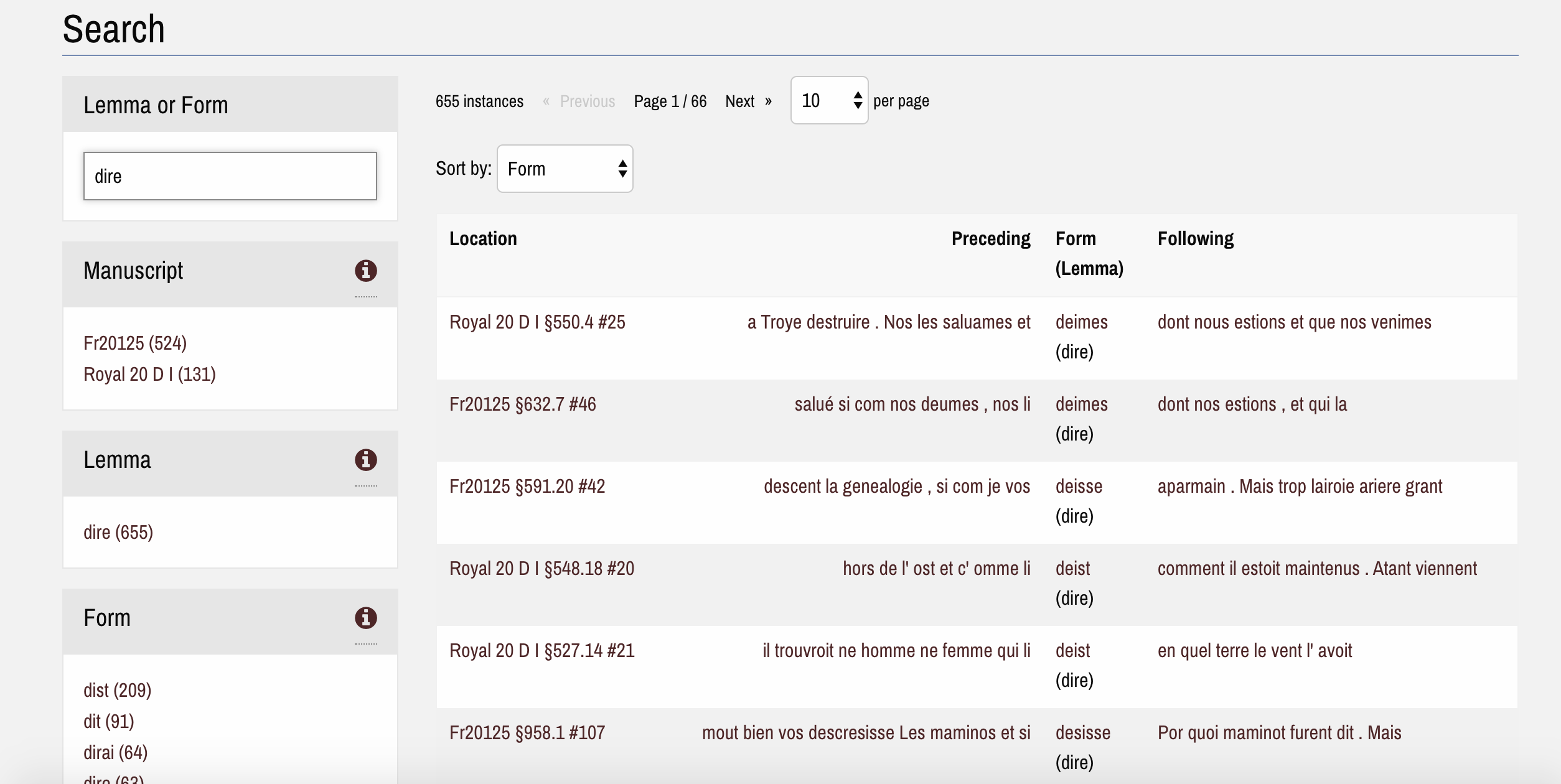
Search: Results if the user searches with the lemma ‘dire’ (to say). Different verb forms are included in the results.
The search results will include every occurrence of the form entered or, alternatively, every occurrence of the forms grouped under the selected lemma. It is possible to sort the results by form, the preceding/following word, and the location in the text of each manuscript.
You can refine your search by using the faceted search menus on the left side of the page. It is also possible to visualise the occurrences of only one manuscript or section, and filter the results according to other relevant parameters (their presence or absence in rubrics, verse sections, or reported speech). At the moment, our lemmatisation does not include the systematic application of a uniform parts of speech standard. However, we have decided to make public some of the grammatical information we have added. Under ‘grammatical attribute’ the user will find morphosyntactic information about: personal pronouns, enclitic determinants and personal pronouns used with prepositions and negative adverbs, past participles, infinitives used with specifiers (inf. substantives), and proper names. A glossary of the search filters is available here.
By clicking on the forms in the ‘Form (Lemma)’ column of the results list, you will be redirected to the edition where you can read the form in its wider context (the relevant segment is underlined in yellow).
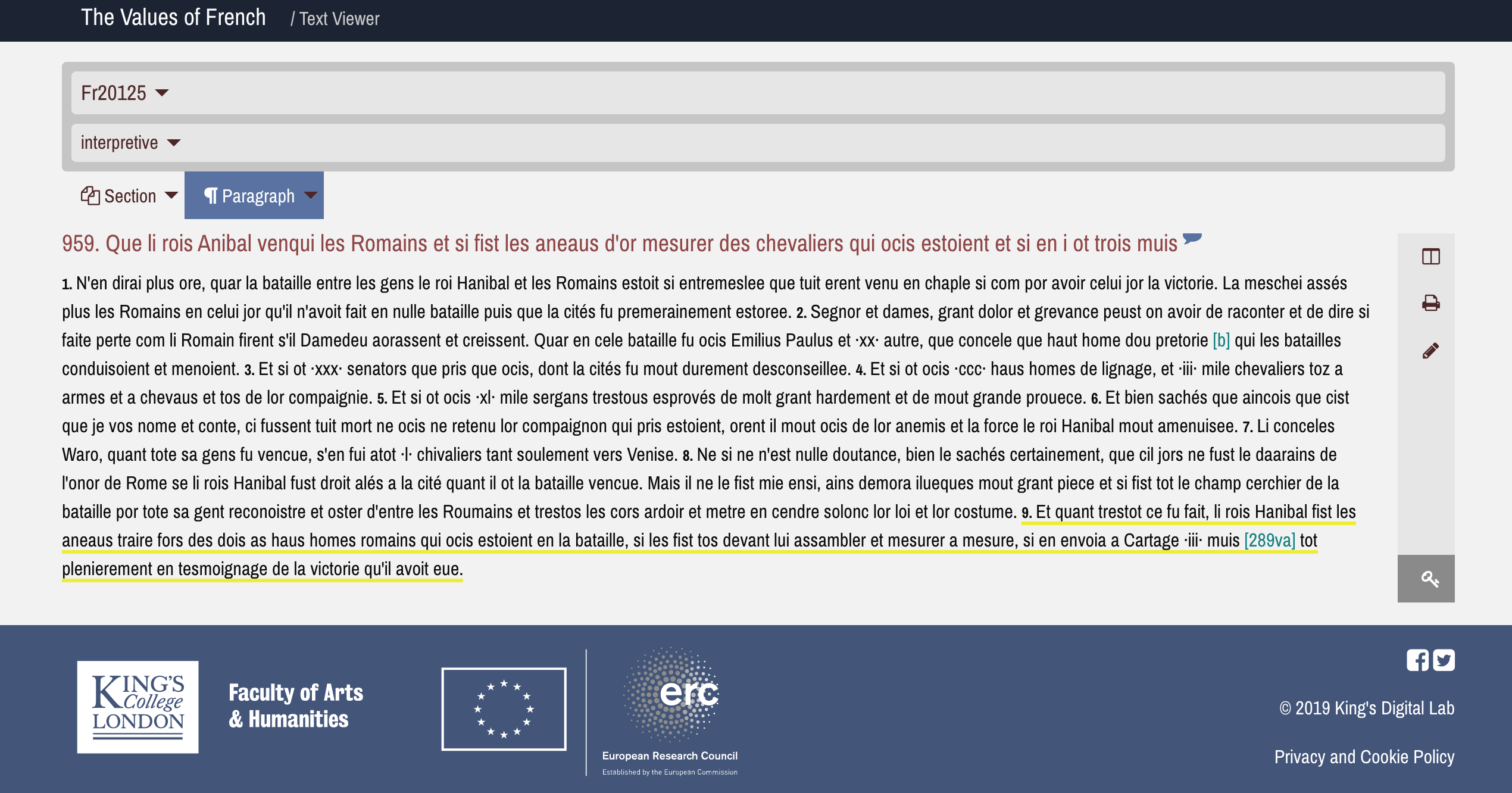
Screenshot taken from our interpretive edition of Rome II in Fr20125.
Behind the scenes: what we have done, what we will do, and where we are going
Search is not only an adaptable tool for navigating the lengthy text of the Histoire ancienne jusqu’à César, it also helps readers to understand the text. Every single form is connected to a lemma. If a user finds a form unclear or even obscure, they can discover its lemma using Search and then look up, when relevant, its definition.
The inclusion of the lemmata has been made possible thanks to the scientific and technical support offered by our colleagues at the DEAF, Stephen Dörr and Marcus Husar (see this blog by Simone Ventura on the beginnings of our collaboration in 2016, or this more recent post by Stephen and Marcus). The process of lemmatisation (i.e. the association of a lemma with a form and the creation of new lemmata) is undertaken manually using Lemming, an intuitive and efficient tool custom designed by Marcus Husar. Lemming operates on the fly and enables multiple users to work on the same data set, allowing the whole team to contribute.
Lemming is fully integrated into our editorial workflow, which has helped to make lemmatisation a key part of our editorial work. A specially designed script tokenises every word in the text (i.e. gives each word a unique numerical id) and then generates a KWIC (Key Word in Context) index using our interpretive text. This KWIC index is uploaded to Lemming. Lemmatising uncovers errors and inconsistencies in our editions and transcriptions. Thanks to a recently developed interface in Lemming, we can re-upload a new KWIC index based on the corrected source files and integrate the corrections into our lemmatised data.
The data on the search page derive from an output file from Lemming. This is matched up with our tokenised source files so additional information such as the encoding of direct/indirect reported speech can be used to refine the search results. For more information on the collaborative editorial workflow check out this poster Hannah presented at DH2019.
Both the text processing workflow and search page are designed by our colleagues in King’s Digital Lab. Their creation and development would not have been possible without the brilliant efforts of Geoffroy Noël, Paul Caton, and Ginestra Ferraro.
Our lemmata are mostly based on the entries in the Altfranzösisches Wörterbuch by Adolf Tobler and Erhard Lommatzsch, also known as ‘Tobler- Lommatzsch’ or ‘TL’. New lemmata have been created for forms which are not included in the TL and for grammatical categories (e.g. adverbs ending in -ment) which have no separate entry in the TL. The adaptation of the TL’s lemmata is a work in progress, which we are undertaking in collaboration with the DEAF team. Our objective is to make our lemmata compatible with the DEAF and, at the same time, to help the DEAF team to include in the dictionary all the new, rare or early attestations found in our editions. Over the next year, we will refine our lexical analysis of the text and hope to contribute to a better knowledge of Old French lexis.
—TVOF team